

Let's Create a Benchmark!
Here we will cover how to actually create a benchmark with your packaged data. We'll do this by looking at a sample benchmark, Ferguson2024, and exploring how it is structured.
This section is divided into eight parts. In Part 1 we'll ensure you have the required packages installed. In Part 2, we'll go over how to access a sample benchmark folder. In Part 3, we'll cover the structure of the sample benchmark folder. In Part 4 through Part 7 we'll examine each of the four files in the sample benchmark folder. And finally in Part 8, we discuss how everything fits together. If you just packaged your data, then you probably can guess what some of these files are: there is an __init__.py file, a test.py file, and a new benchmark.py file. Each will be explored in detail below.
Part 1: Install Necessary Packages
If you have not already, we highly recommend completing the 'Package Data' section before beginning this second part of the tutorial. Although completion is not strictly required, the Package Data section will give you a nice background into the stimuli and data side of a Brain-Score benchmark.
If you have already done the Package Data tutorial, feel free to skip to step 2 to the right. Otherwise, visit please the Package Data tutorial to install the necessary packages for Brain-Score and to learn more about stimuli and data packaging.
Part 2: Access the Sample Benchmark Submission Folder:
As was the case for the Package Data tutorial, we will be looking at a sample benchmark, Ferguson2024, in order to understand the many parts of a benchmark plugin. You can view our sample submission folder in your local copy of Brain-Score that you cloned in Part 1; the folder we are going to be exploring is vision/brainscore_vision/benchmarks/ferguson2024. If you cannot access a local copy of Brain-Score, the sample benchmark folder is also available on our Github here.
Currently (as of August 2024), benchmark submission via the website are a little buggy. Once you have your submission ready to go, reach out to Brain-Score Team member and we will submit your benchmark for you via a Github PR.
Part 3: Exploring the Sample Submission Folder
The Benchmark brings together the experimental paradigm with stimuli, and a Metric to compare model measurements against experimental data. The paradigm typically involves telling the model candidate to perform a task or start recording in a particular area, while looking at stimuli from the previously packaged StimulusSet. Typically, all benchmarks inherit from BenchmarkBase, a super-class requesting the commonly used attributes. These attributes include the identifier which uniquely designates the benchmark , the version number which increases when changes to the benchmark are made a ceiling_func that, when run, returns a ceiling for this benchmark the benchmark’s parent to group under e.g. V1, V2, V4, IT, behavior, or engineering (machine learning benchmarks), and finally a bibtex that is used to link to the publication from the benchmark and website for further details (we are working on crediting benchmark submitters more prominently in addition to only the data source.)
If you completed the "Package Data" tutorial, this folder should look very familiar. It has all the parts needed of standard Brain-Score plugin (remember: a plugin can be a benchmark, a model, a metric, or data - we took a look at a data plugin previously in the first part of this tutorial series). In this folder you can see an __init__.py file for adding your benchmark plugin to Brain-Score's registry, a benchmark.py file that contains the code to run models on your stimuli and compare it to your data, a requirements.txt file for any dependencies your benchmark might need, and finally a test.py file to create certain tests for your benchmark.
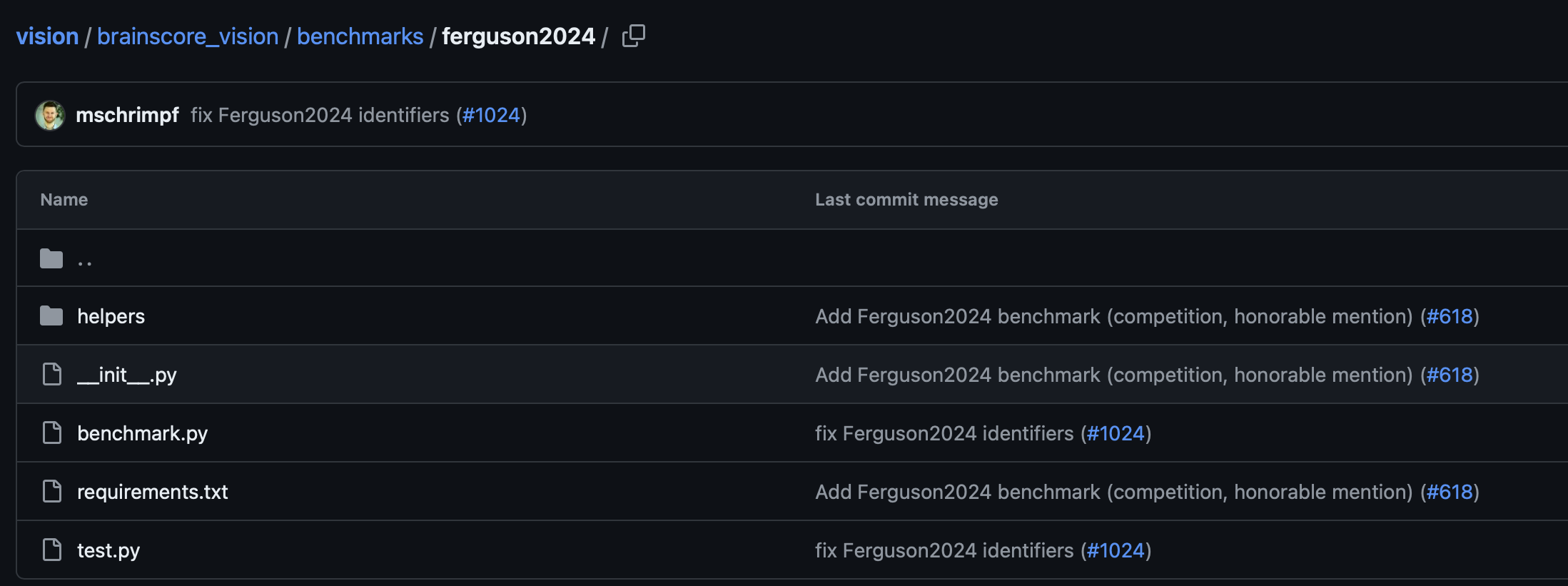
There is also an extra folder, called helpers, that contains an additional python file helpers.py. This is not needed for every benchmark, but contains helper functions that the benchmark calls, including methods for subject statistics, result post-processing and amongst others. We will largely be ignoring this file, but if your hypothetical benchmark required preprocessing functions, human data processing functions, or anything else, this is a good way to abstract them away from the main benchmark.py file; however this is not strictly needed.
Note: this would also be the same overall structure as your submission package, or if you are submitting any other plugins (models, metrics, or data). Feel free to base your future submissions off of this package.
Part 4: Exploring the __init__.py file
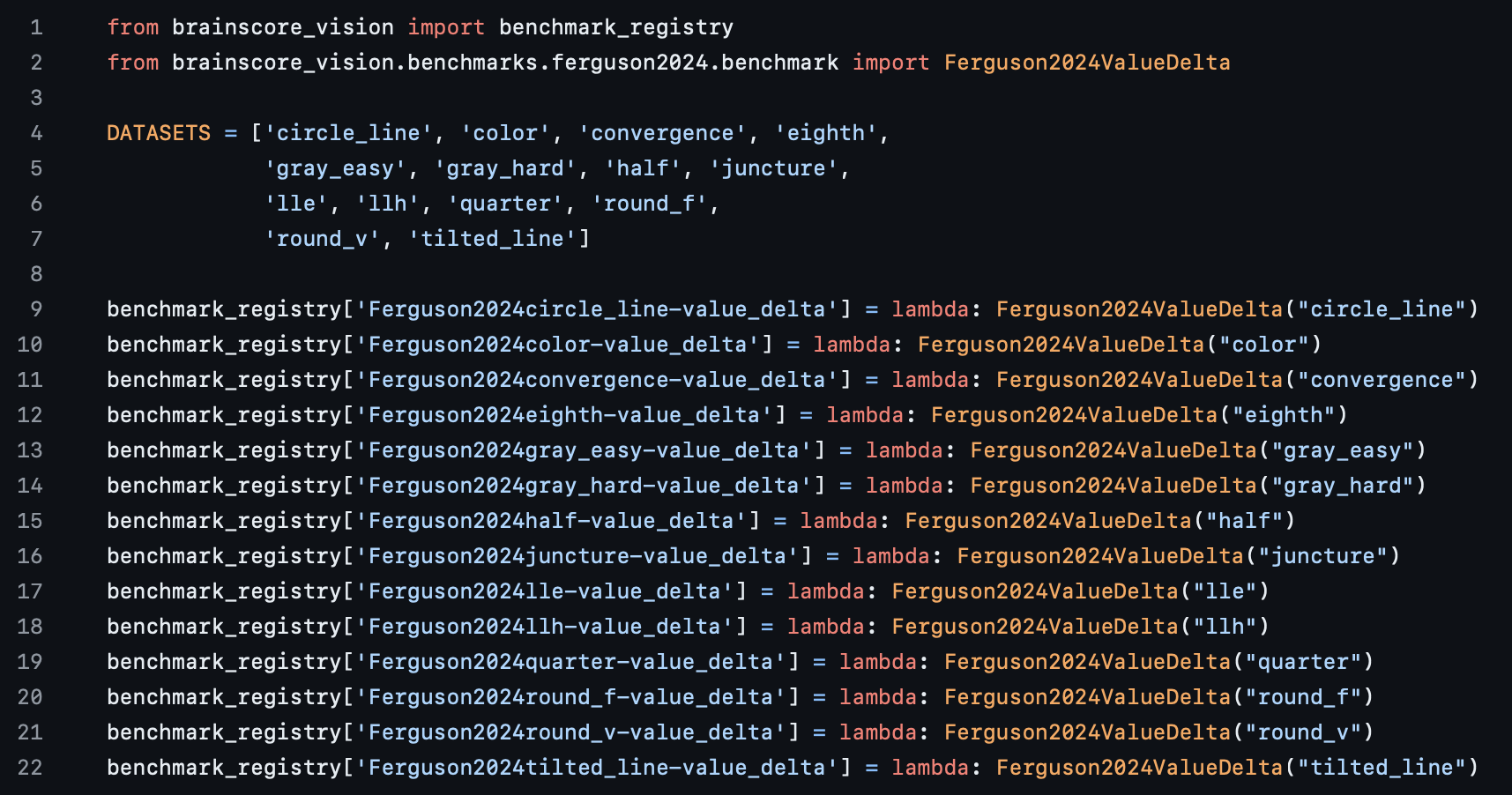
This file is basically the same as its cousin file we looked at in Package Data - it adds a benchmark, for example Ferguson2024circle_line-value_delta, to the Brain-Score registry via the dictionary on lines 9-22. For a benchmark plugin, the key in the dictionary is the benchmark name, and its value is a benchmark object, which we will see soon.
You can see here that there are 14 benchmarks that are being added to the registry, and in the case of our Ferguson2024 benchmark, these are 14 "sub benchmarks" that each use a different StimulusSet and BehavioralAssembly (explained in the previous half of this tutorial). These 14 benchmarks belong to a parent benchmark object, Ferguson2024, and are called via the 14 lambda expressions with a different stimuli and data identifier. For benchmarks in general, we follow the naming convention of AuthorYEAR-metric , as shown here in the screenshot. For metric plugins, identifiers are typically descriptive (e.g. rdm, pls, accuracy).
Please note: Brain-Score does not allow duplicate plugin names, so if you submit another version of the same benchmark, make sure to make the identifier unique!
Also note: It would be prohibitively time- and resource-consuming to actually load every plugin in a registry before they are needed, so the plugin discovery process relies on string parsing. This unfortunately means that it’s not possible to programmatically add plugin identifiers to the registry; each registration needs to be written explicitly in the form of plugin_registry['my_plugin_identifier'] Next, let’s check out the second file, requirements.txt file.
Part 5: Exploring the (optional) requirements.txt File
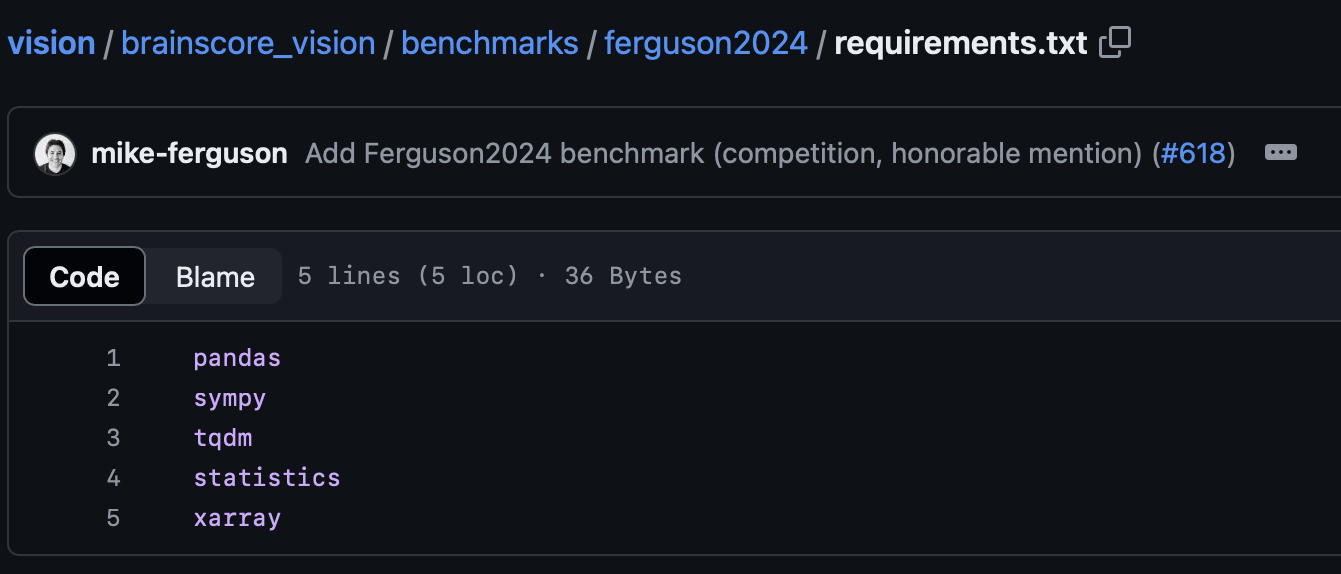
As with all Brain-Score plugins, you can use a requirements.txt to define any needed dependencies. If you do not include any external packages used here, such as numpy, sympy, and pandas, then your benchmark will not be able to run on our servers (this will be caught in Github's PR tests). The reason that this is optional is if your plugin does not need any external packages, then you do not need to submit this file.
Part 6: Exploring the benchmark.py File
This file is arguably the most important file for the benchmark, as it defines how models will see stimuli, have their responses recorded, and compared to humans. There are many parts to this file, so we will look at a few lines at a time, starting with the benchmark class's __init__method.
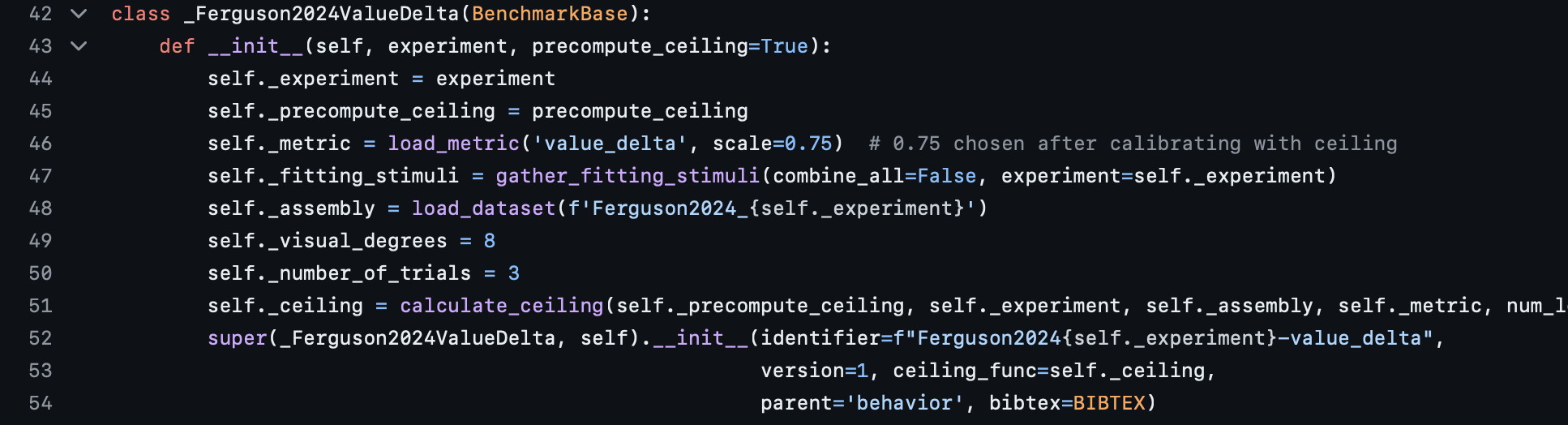
The __init__method shown above on lines 43-54 is what is called to initialize your benchmark. Lines 44-51 all set important hyperparameters: the metric, the visual degrees, the number of repetitions, and other fields that the benchmark uses. Lines 52-54 specifically call the super constructor to tell Brain-Score that each of these benchmarks are a part of the parent benchmark Ferguson2024ValueDelta.
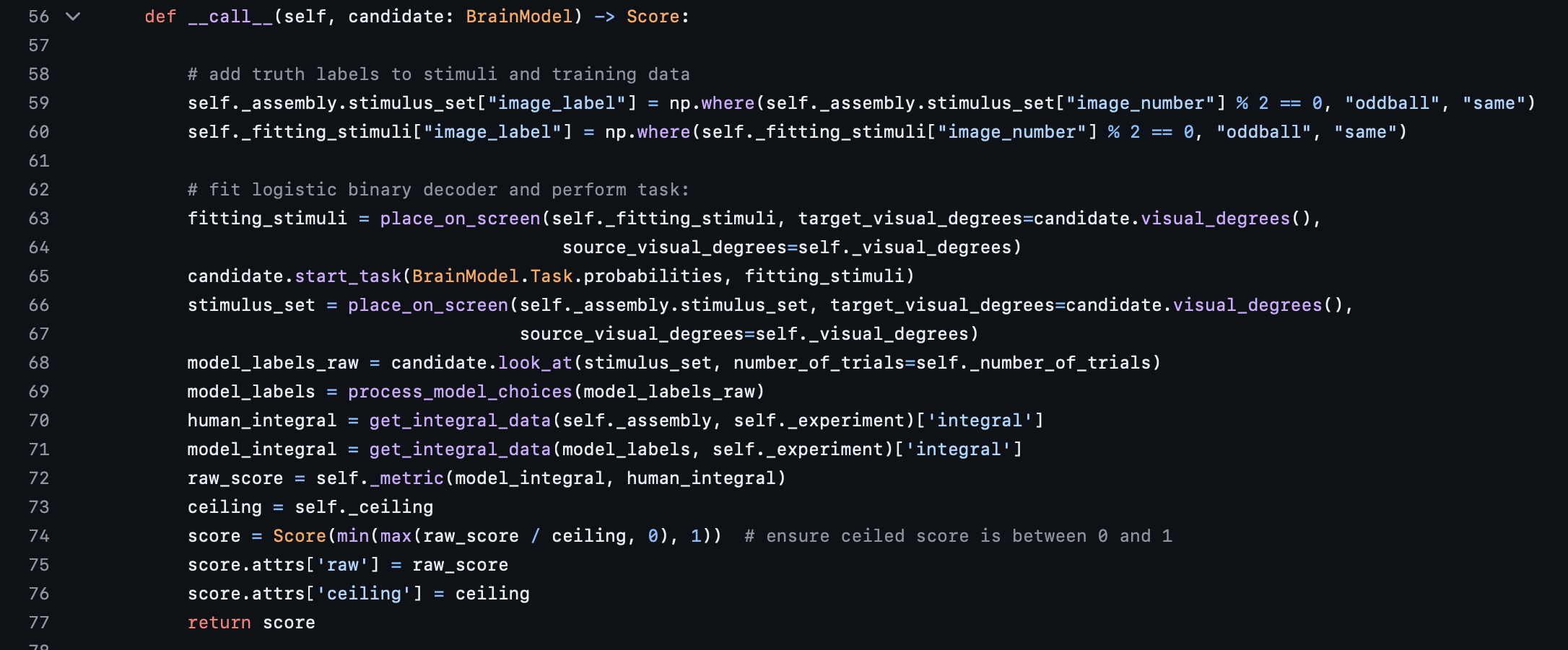
Next, the __call__ method shown above has many important parts, and we will look at each one of them. In an nutshell, this method is what actually shows the model the stimuli, computes a model score, and compares that score with a human score via a metric to determine the final Brain-Score.
Let's start with Lines 63 and 64: here the place_on_screen Brain-Score method is called to transform your stimuli into visual degrees. The particular call on line 63 is for pretraining (transfer-learning) the models to allow them to be able to do a binary classification task. For background, the Ferguson2024 benchmarks asked the subject to look at an image of objects, and return whether or not that image contained an "odd-one-out". So for models not trained explicitly to perform binary classification, this pretraining on line 63 and the decoder itself on line 65 force a binary output from the model, using a logistic regression decoder. Note: your benchmark might be completely different as far as the task goes; Brain-Score has many other tasks supported, and you can always contribute a custom one! Finally, Lines 66 and 67 call the place_on_screen method for the actual testing stimuli themselves, in order to show them to the model.
Next, line 68 is what actually shows the model the stimuli and returns a binary label for each stimulus, contained in this case inside the model_labels_raw variable. Line 69 applies some post-processing on these labels in order to get them to be more human-readable; if you were creating your own benchmark, you could probably ignore these.
Lines 70 and 71 get the "human score" and the "model score" respectively. Again for context, the Ferguson2024 benchmarks work by comparing a human integral of a specific graph with one generated by models. This is just one way to quantify human and model performance, and each benchmark has its own method of doing this. Line 72 is where these two scalars are passed into a metric in order to be compared. In this case, that metric is a simple value delta using a sigmoid curve. This metric takes in two scalars and returns a value between 0 and 1 based on how similar the two scalars are. You can use any metric you want if you are creating your own benchmark, or even create a custom metric as well. Please see here for a list of currently supported Brain-Score metrics, and note that many use human data directly (via assemblies) or a processed version (via a matrix of some description).
Next comes the benchmark ceiling. A ceiling represents the maximum score a perfect model could achieve on the data, and might not always be 1. Line 73 calls the ceiling method defined in lines 84-116, and simply splits the human data in half randomly many times, computes the metric on those two halves, and returns the average. Although you could choose any ceiling you desire, we strongly encourage you to use the exact same metric you used to compare models with subject data in your ceiling, as we believe this is a best practice. You can also precompute your ceilings, and we encourage this as well. You can see this reflected in lines 30-34, where a dictionary is used to store precomputed ceilings per dataset to save compute resources.
Finally, lines 74-77 adjust the raw score by the ceiling, and then returns it. Also note that lines 80-81 define the function used in the benchmark's __init__.py file, and if you are making your own benchmark, do not forget to include this. The rest of the lines after line 81 are extra helper functions for the benchmark, and can be ignored for now.
Part 7: Exploring the test.py File
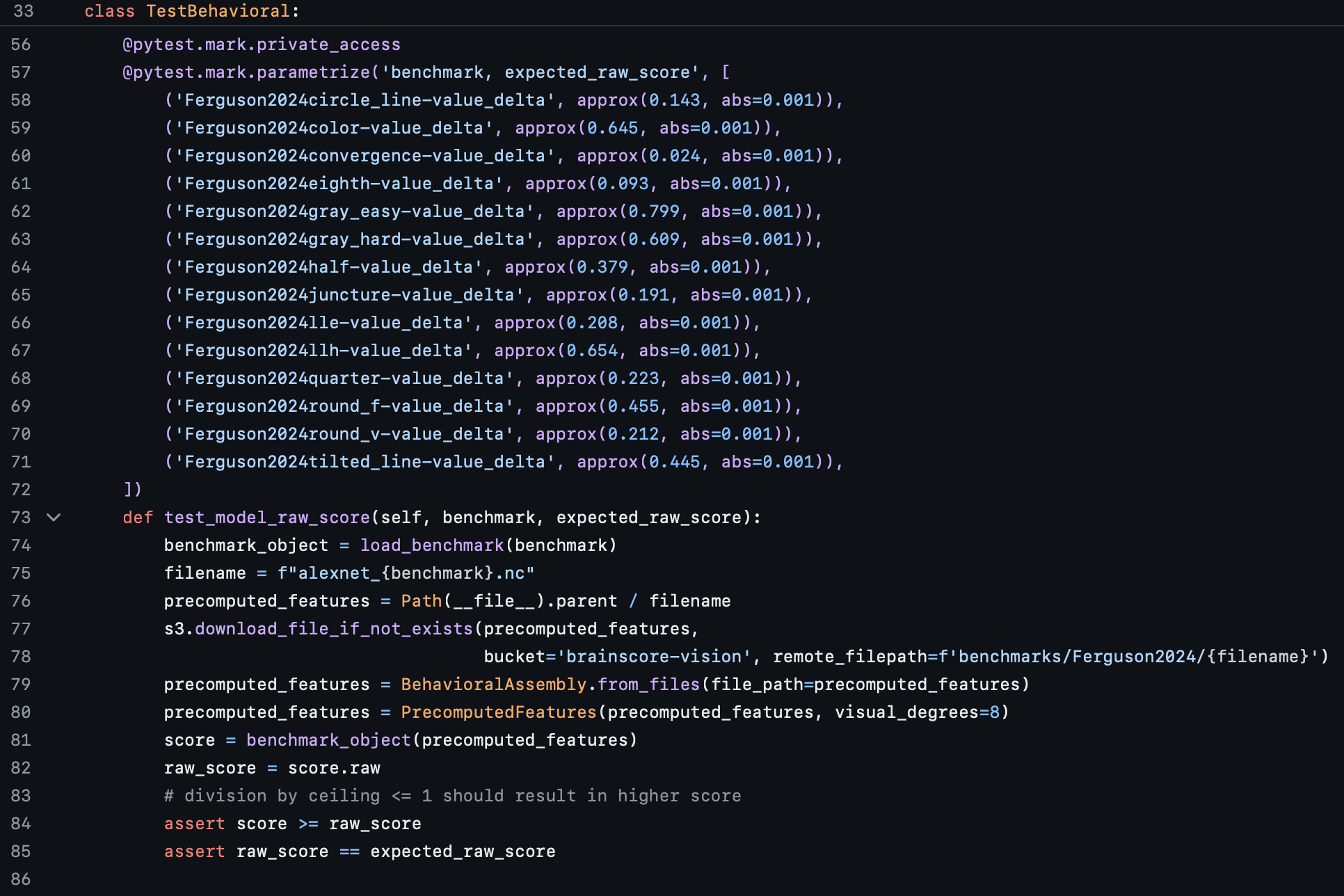
Our test.py file serves the purpose of testing our benchmark to ensure scores are coming out as expected. There is a little bit of a circular dependency here, as you will not know scores until you actually run your benchmark; however, you can run 1-2 models locally, and hardcode th expected model scores into your tests, which is what is done in the screenshot above.
On lines 58-71, you can see that each of the 14 benchmarks have an expected raw score associated with them that is passed into a Pytest object. These scores were generated via a local call to Brain-Score, and you can learn more about how to do that by visiting the model tutorial Quickstart.
Line 73 defines the function test_model_raw_score, and that is what is seen in lines 74-85; we are loading a benchmark and a precomputed model's features on that benchmark, and them comparing that to an expected score. Note: to do this successfully requires uploading precomputed model features to our S3 bucket (however, you can also host externally); please contact a Team Member if you need credentials to do this. For more information on how to generate precomputed model features for your tests, please see here (The "Precomputed features" section, and you can ignore steps 5 and 6 that are now outdated).
There are also other tests that are in the test.py that are simply not shown in the screenshot above. These include tests for existence of the benchmark, tests to ensure the benchmark ceiling is working correctly, and tests to make sure the ceiled score is what it should be. Please feel free to base future submission tests off of this sample file!
Part 8: Putting it All Together
By now you have seen the heart of a benchmark, and hopefully feel comfortable enough with the benchmark plugin system that you could upload your own. We recognize that this might be a tedious process that is bound to raise questions, so please reach out to Team Member if you would like help getting your benchmark on our site.
If you were submitting your own benchmark plugin, then after you make sure you have all the files that you need, you could send them to a Brain-Score team member and we would open a PR for you, where you can track progress on your contribution. Once the PR's tests pass and it is merged, your benchmark will be scored on the top 100 models!
If you have any more questions, please see the benchmark section of our troubleshooting page here.

Our tutorials and FAQs, created with Brain-Score users, aim to cover all bases. However, if issues arise, reach out to our community or consult the troubleshooting guide below for common errors and solutions.